Prosenjit Chakraborty || প্রসেনজিৎ চক্রবর্তী
Email: prosenjitchakrabortyrmstu@gmail.com





Prosenjit Chakraborty || প্রসেনজিৎ চক্রবর্তী
Email: prosenjitchakrabortyrmstu@gmail.com
A graduate of Rangamati Science and Technology University with a B.Sc. (Engineering) in Computer Science and Engineering. My passion lies in the fields of Machine Learning, Natural Language Processing (NLP), Computer Vision, and Deep Learning. Throughout my academic journey, I have been deeply engaged in research, contributing to various projects that explore innovative solutions in these areas. My portfolio is a showcase of the work I've done, the research I've published, and the skills I've honed through relentless curiosity. Check out my work, and let’s team up to explore new tech possibilities!
1. A hybrid aprroach for Bengali sentence validation
Juel Sikder†, Prosenjit Chakraborty†, Utpol Kanti Das and Krity Dhar
† These authors contributed equally to this work.
Bengali is the official language of Bangladesh and is widely used in Bangladesh and West Bengal in India. Due to the growing accessibility of the internet and smart devices, the use of digital text material and documents in Bengali is growing with time. An automated Bengali Sentence Validation System is proposed in this study to effectively determine the correctness of sentences in such extensively available Bengali content. As far as we know, no substantial work has been done in the field of Bengali Sentence Validation utilizing deep learning approaches. Due to the lack of linguistic resources, sophisticated Natural Language Processing tools, and benchmark datasets, developing an automated Sentence Validation System for a limited-resource language like Bengali is challenging. Additionally, Bengali Sentences come in two morphological varieties (Sadhu-bhasha and Cholito-bhasha), making the validation process more challenging. The proposed automated Bengali Sentence Validation system contains the CNN-BiLSTM hybrid classifier model. As of now, there is no standard dataset for Bengali sentence validation. Due to the lack of a standard dataset, we collected Bengali sentences from different sources in Bangladesh and developed a Bengali Sentence Validation (BSV) Dataset with around 5000 labelled sentences arranged into two categories such as correct and incorrect. Experimental results demonstrate that the proposed system outperformed other classifier models and existing approaches for Bengali Sentence Validation and is able to categorize a wide range of Bengali sentences based on their correctness. The system’s F1 score for the Bengali Sentence Validation is 98%.
2. Bengali handwritten equation solving system
Utpol Kanti Das, Juel Sikder, Nippon Datta and Prosenjit Chakraborty
The goal of this research is to detect, recognize and solve mathematical equations, especially Bangla handwritten equations using a deep learning-based model and JUBHEC (Juel & Utpol’s Bengali Handwritten Equation Converter) method. We are going to suggest a merged model (region-based Convolutional Neural Network (mask-R-CNN) and Feature Pyramid Network (FPN) i.e. Bengali Handwritten Equation Detector (BHED)) to detect and recognize Bengali handwritten equations and the JUBHEC method to convert the detected Bengali handwritten equation into computerized form. We have also used BODMAS (Bracket, Of, Division, Multiplication, Addition, Subtraction) principles and different data structure techniques to solve Bangla handwritten equations. We have also introduced the Bengali Handwritten Arithmetic Equations Dataset (BHAED), which has 1000 images, 23 classes, and 28 954 instances, and created polygon shape ground truth for the BHAED dataset. The system has given 99.2% accuracy for fast-RCNN character classification, 98% accuracy for fast-RCNN foreground box classification and 96% accuracy for mask-RCNN instance segmentation of characters.
3. Heartbeat Sound Analysis: Integrating Deep Learning Models for Classification
Tahmina Akter, Tanjim Mahmud, Utpol Kanti Das, Prosenjit Chakraborty, Nahed Sharmen, Mohammad Shahadat Hossain and Karl Andersson
Heartbeat sound signal classification has been extensively researched in the field of medical signal processing, with various approaches proposed to address the challenges associated with accurate and efficient classification. The objective of this research is to develop an accurate and efficient heartbeat sound signal classification system using hybrid deep learning models. Various deep learning models including CNN, RNN, LSTM, BiLSTM, and GRU are compared with the proposed model. The performance of each model is evaluated based on the classification accuracy, and the results demonstrate that the proposed models achieve high accuracy rates. The hybrid model has been constructed by combining random forest (RF) with each deep learning model. The hybrid models outperform the standalone deep learning models, with RF+CNN achieving the highest accuracy rate of 94.43%, followed by RF+LSTM (94.38%), RF+GRU (94.09%), and RF+BiLSTM (93.85%). The proposed hybrid deep learning models provide a promising approach for the accurate classification of heartbeat sound signals, which has significant implications for early diagnosis and treatment of cardiovascular diseases.
4. A Machine Learning Ensemble Approach For Understanding The Consumer's Degree of Satisfaction
Prosenjit Chakraborty, S.M. Golam Sarwar Apu and Juel Sikder
Accepted (EISBG 2024)
To be added after publication.
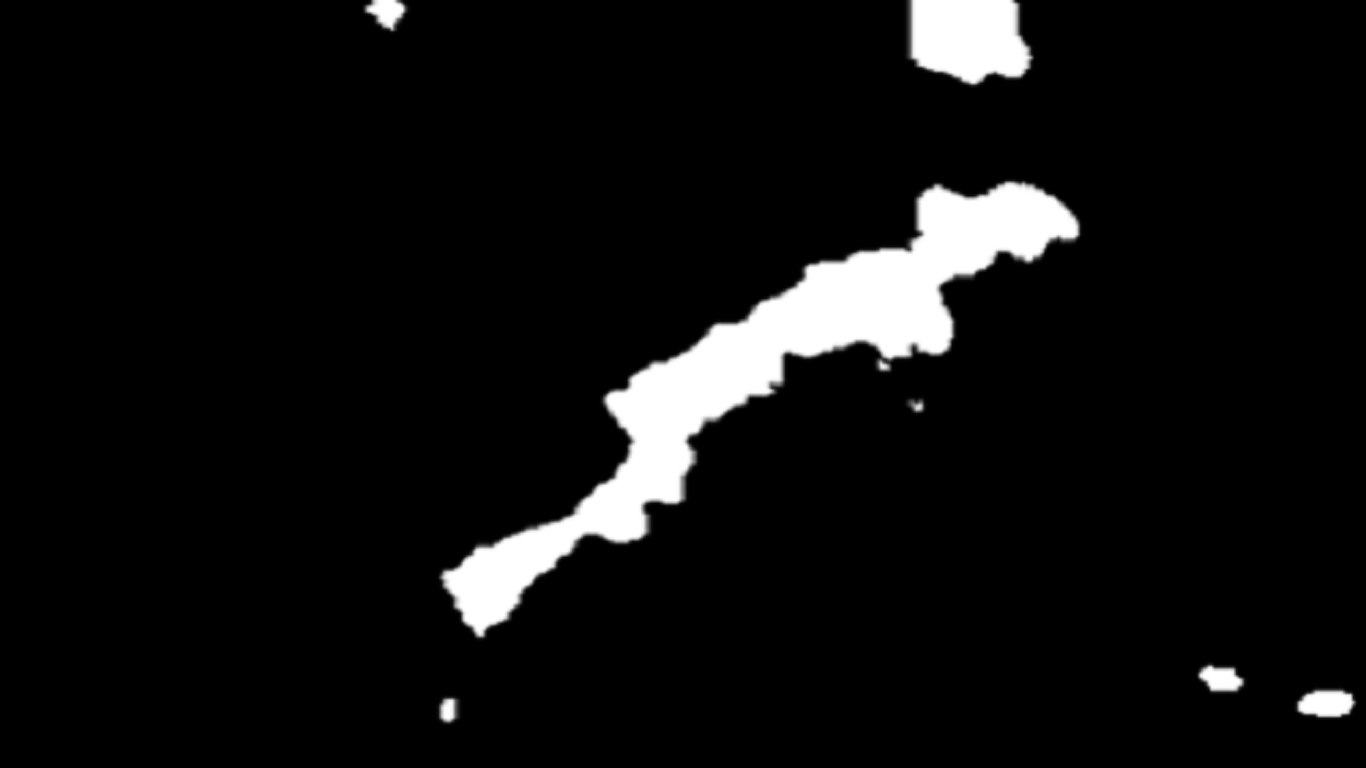
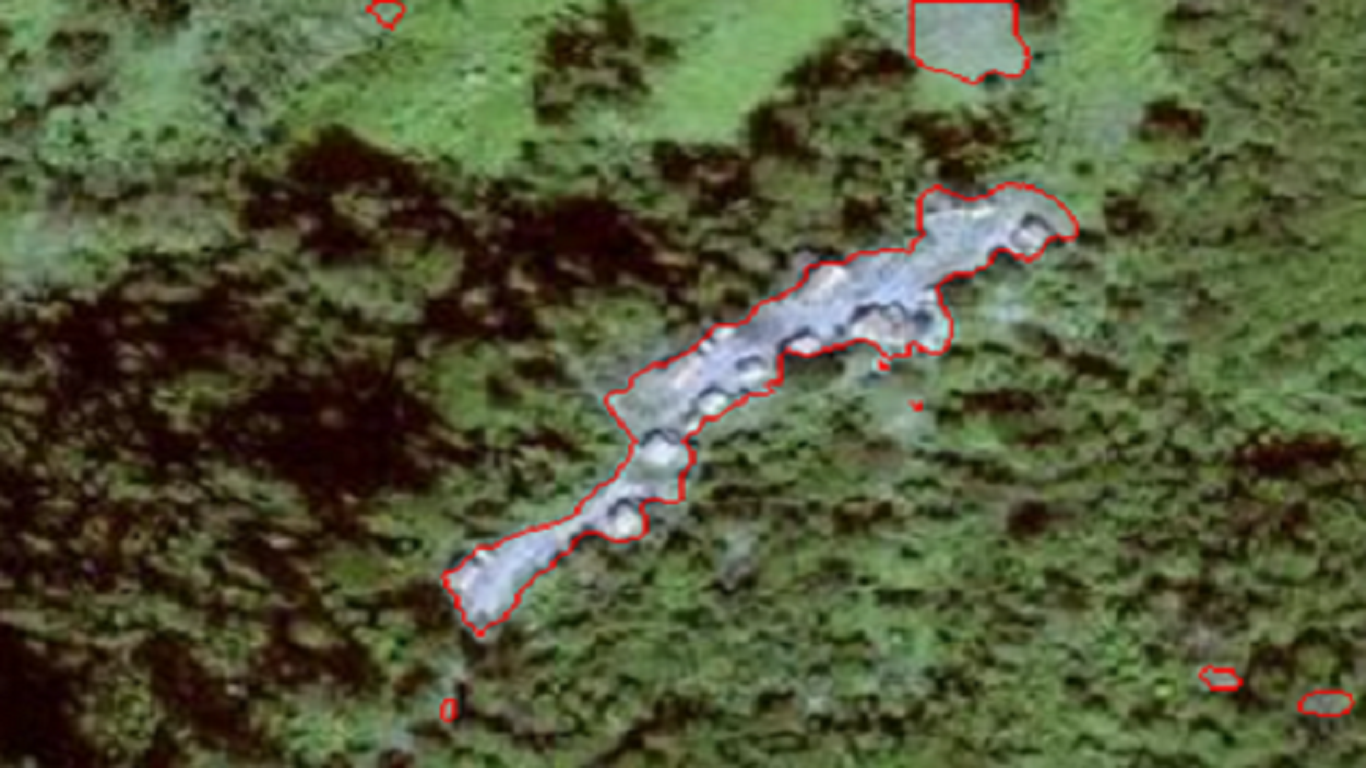
5. Deforestation Detection in Rangamati Using A Customized UNet
Juel Sikder, Prosenjit Chakraborty, Utpol Kanti Das and Nippon Datta
(Under Review)
To be added after publication.
6. Breast cancer classification and segmentation framework using BCC-CNN and BCC-U-Net
Juel Sikder, Krity Dhar, Utpol Kanti Das and Prosenjit Chakraborty
(Under Review)
To be added after publication.
Browse My Recent
Deforestation Detection System for Rangamati Hill Tracks
Objective: Detect and calculate the deforestation area from the given images of Chittagong Hill Tracks.
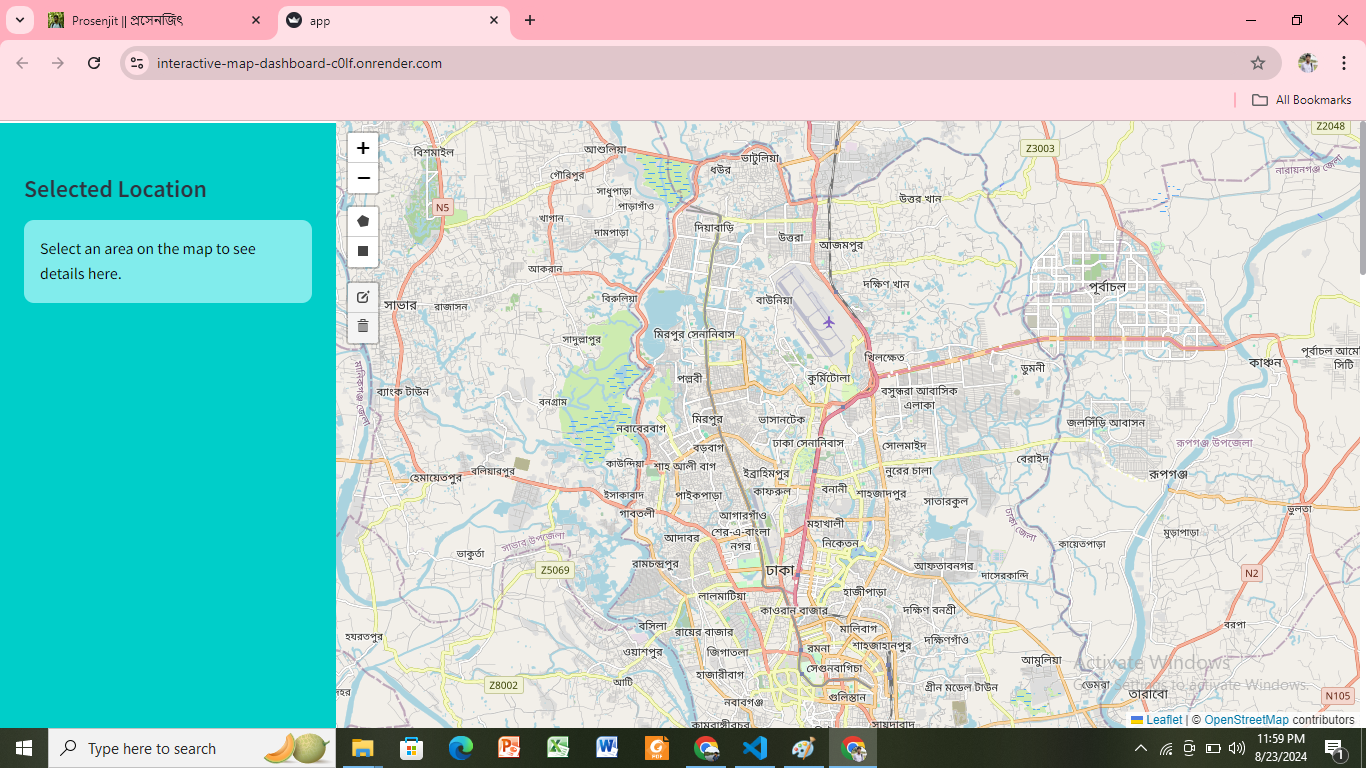
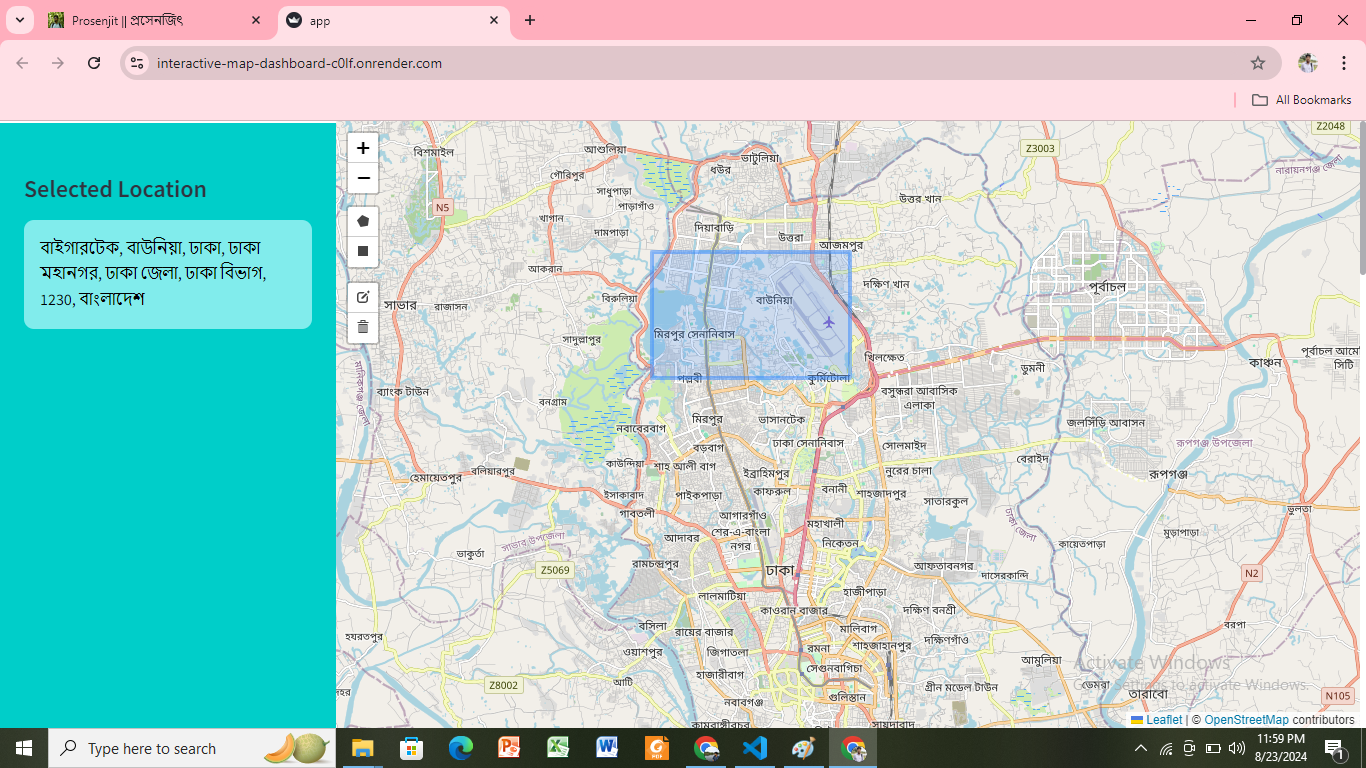
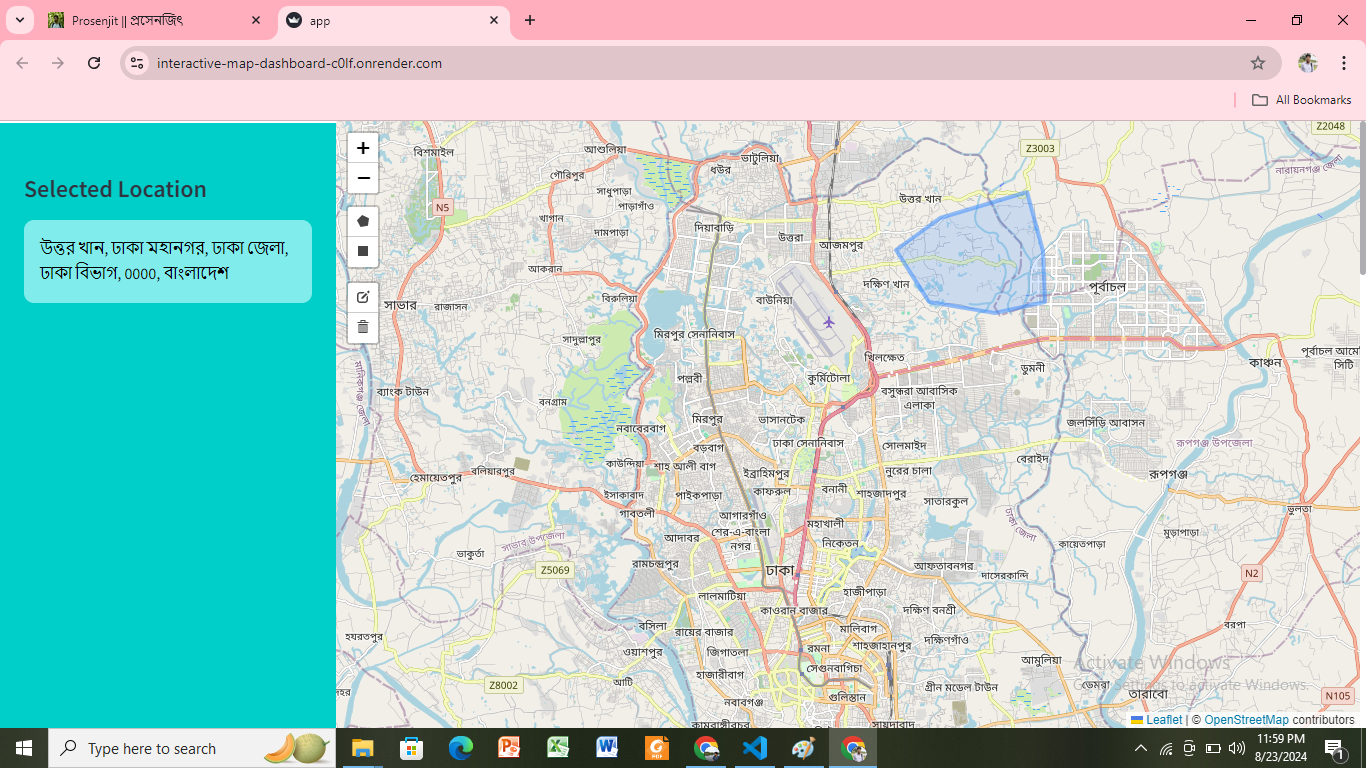
Interactive Map Dashboard for Detailed Location Analysis
Objective: An interactive map dashboard that allows users to explore and analyze specific areas by selecting square or rectangular regions on a high-resolution map. The selected area will display concise and relevant details in a sidebar, providing users with immediate insights about the location.
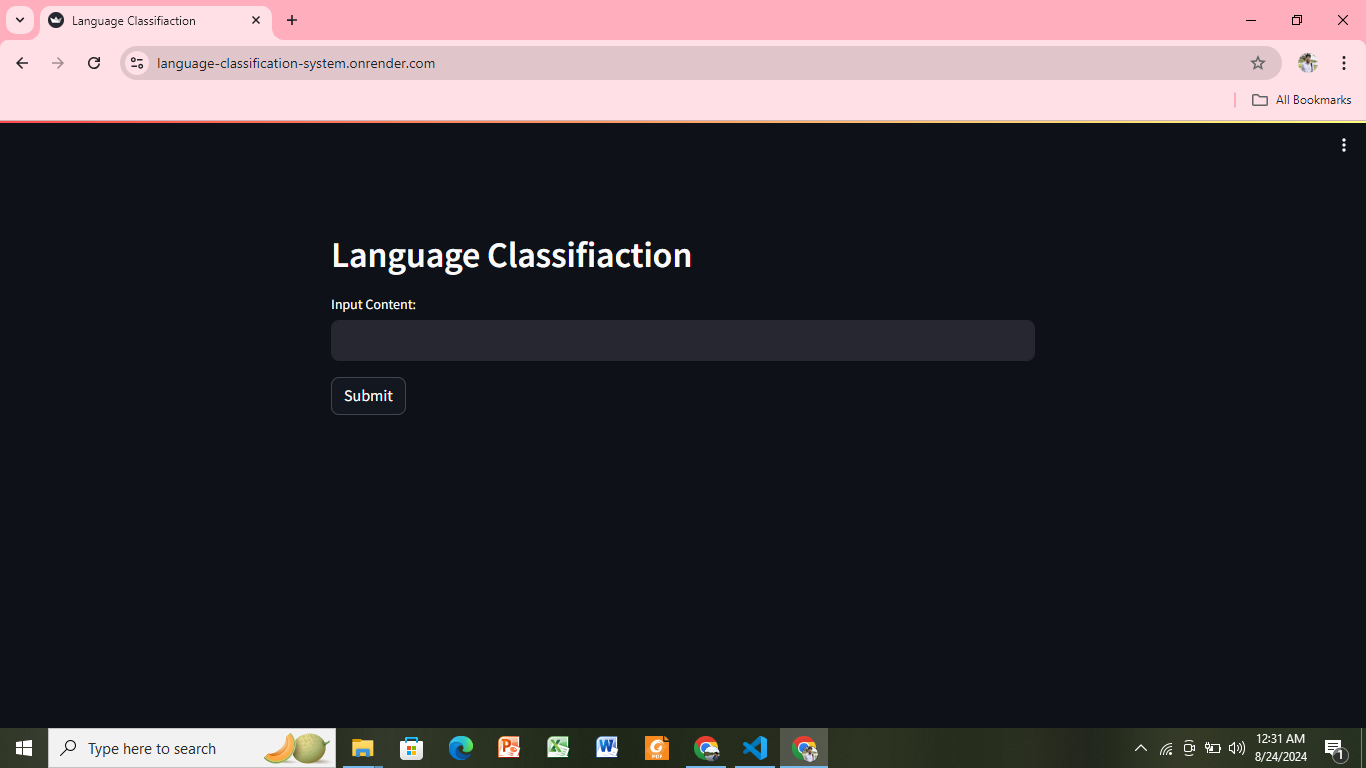
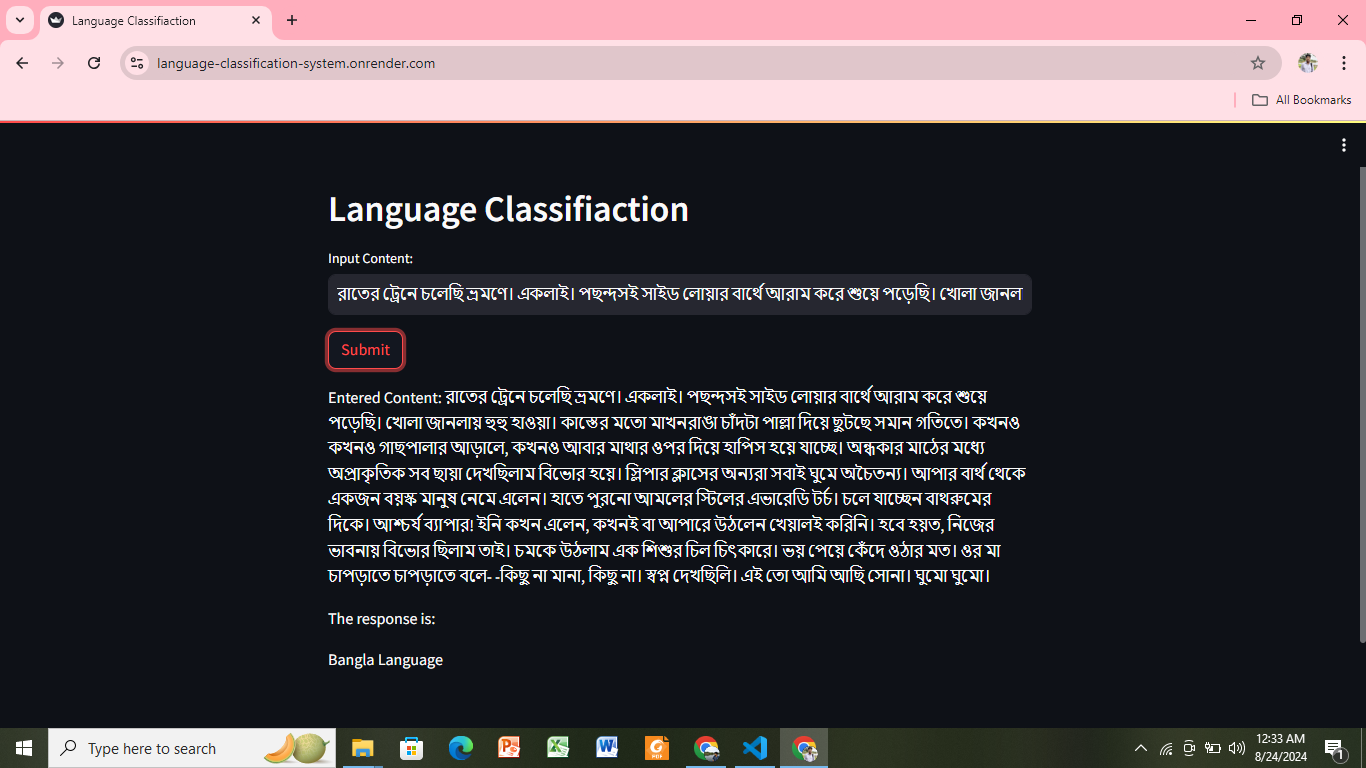
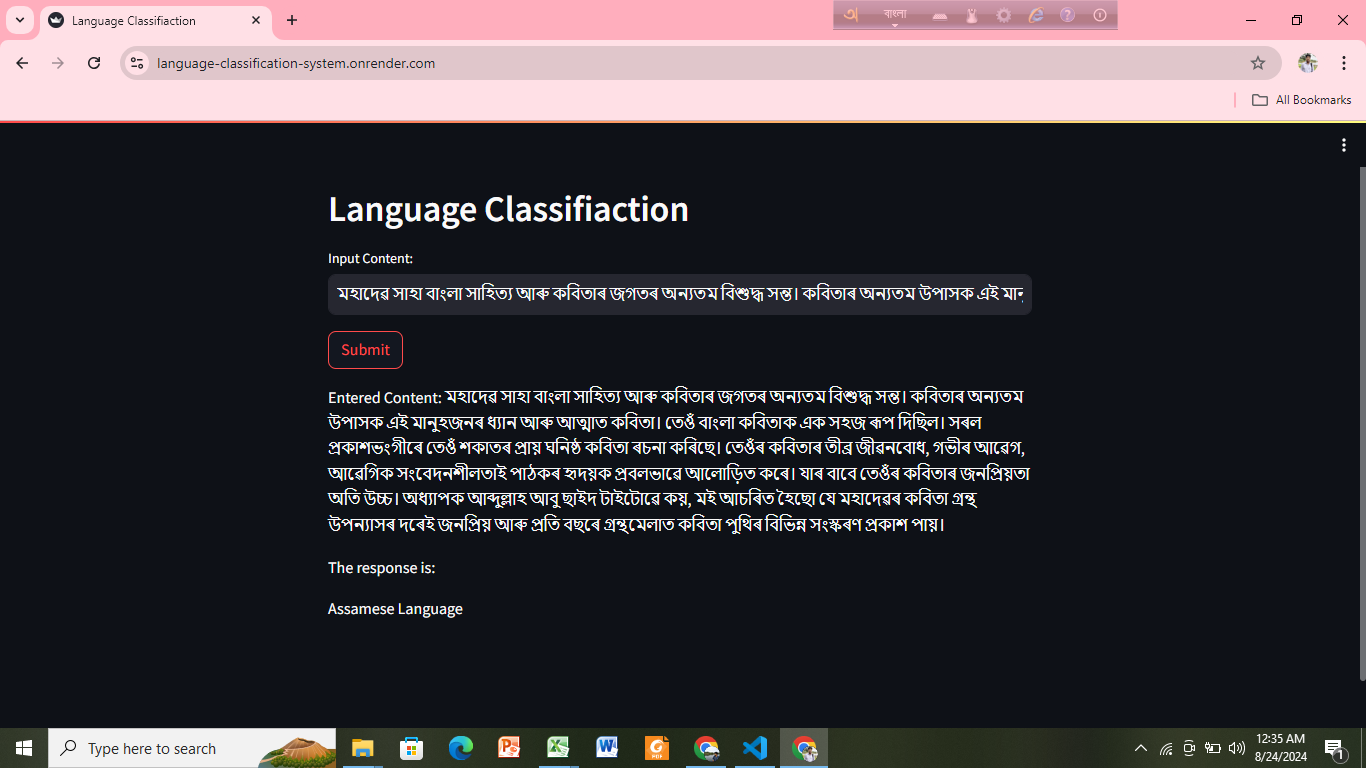
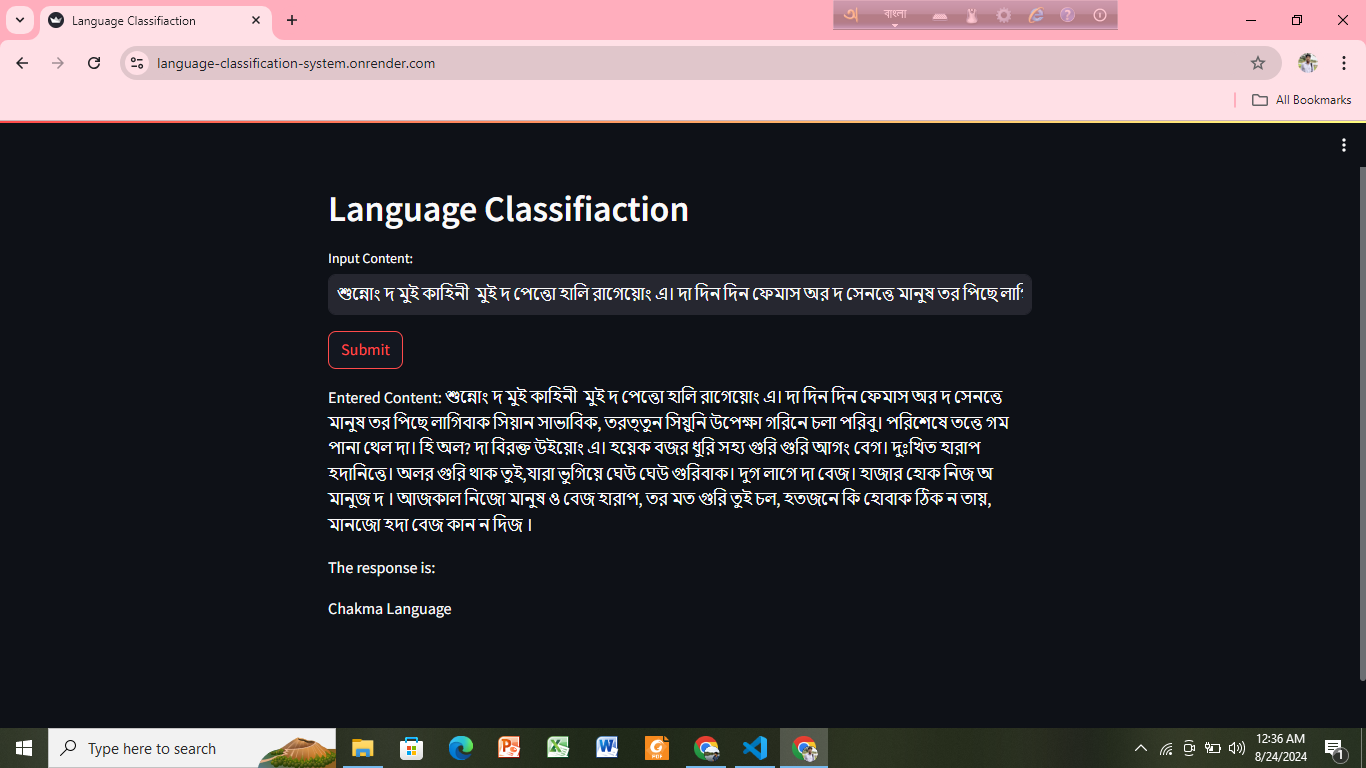
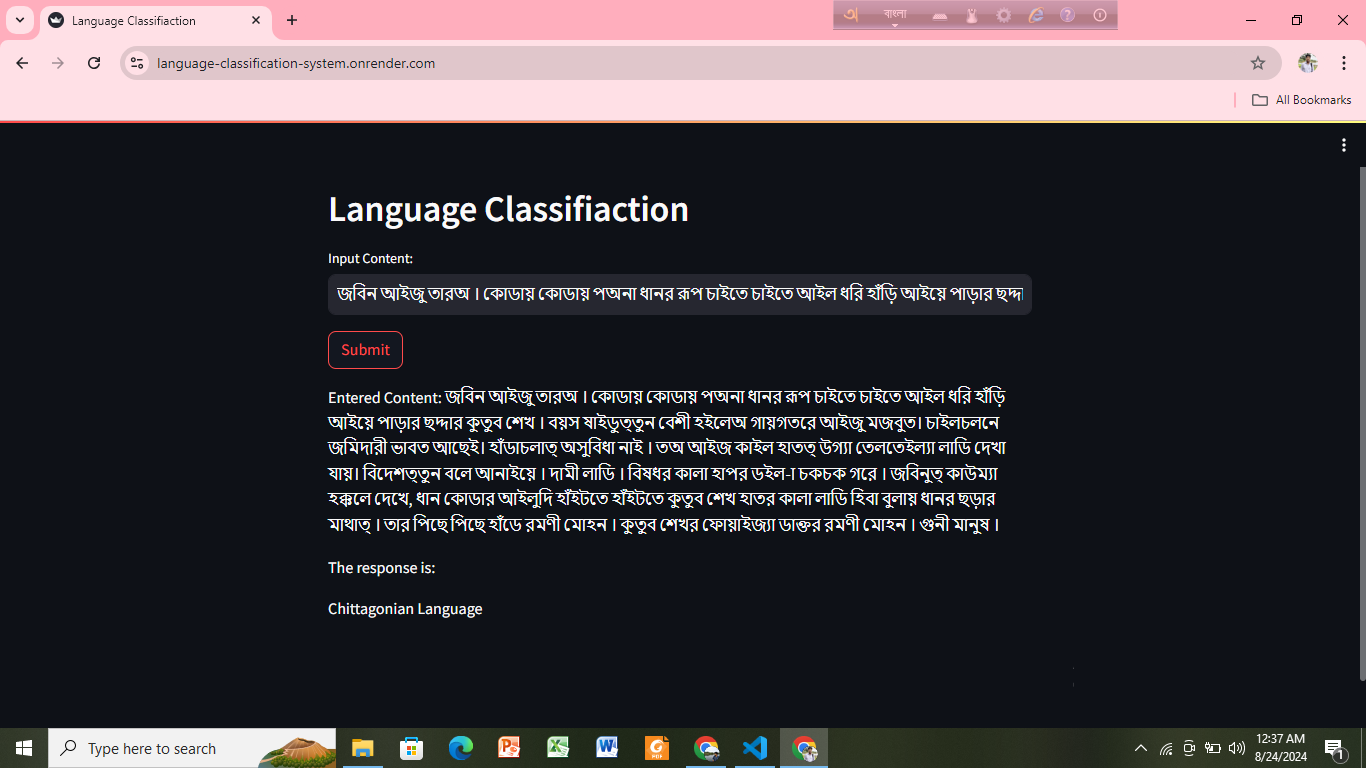
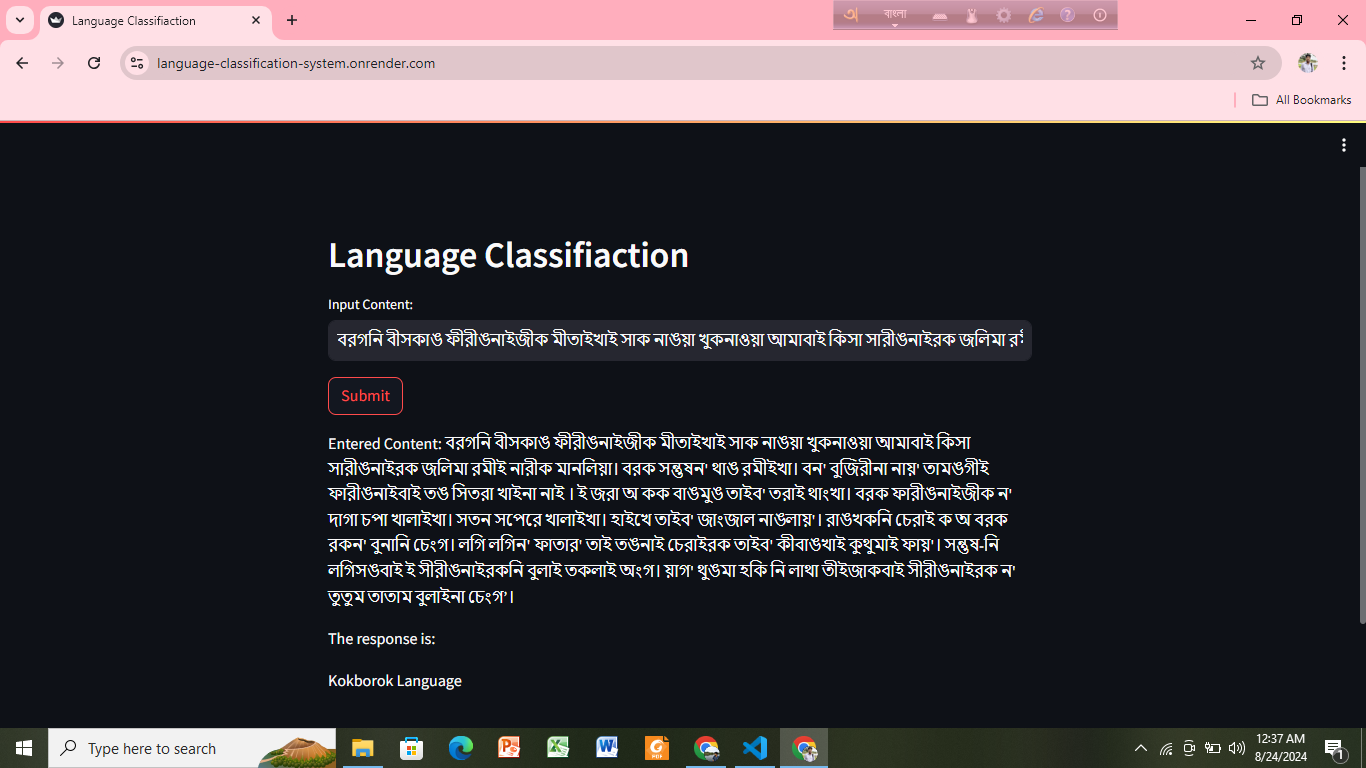
Machine Learning-Based Language Classification of Multilingual Content Written in Bengali
Objective: Classify the original language (such as Assamese, Chakma, Kokborok, Chittagonian, Sylheti and Bengali) of the content written using the Bengali alphabet.
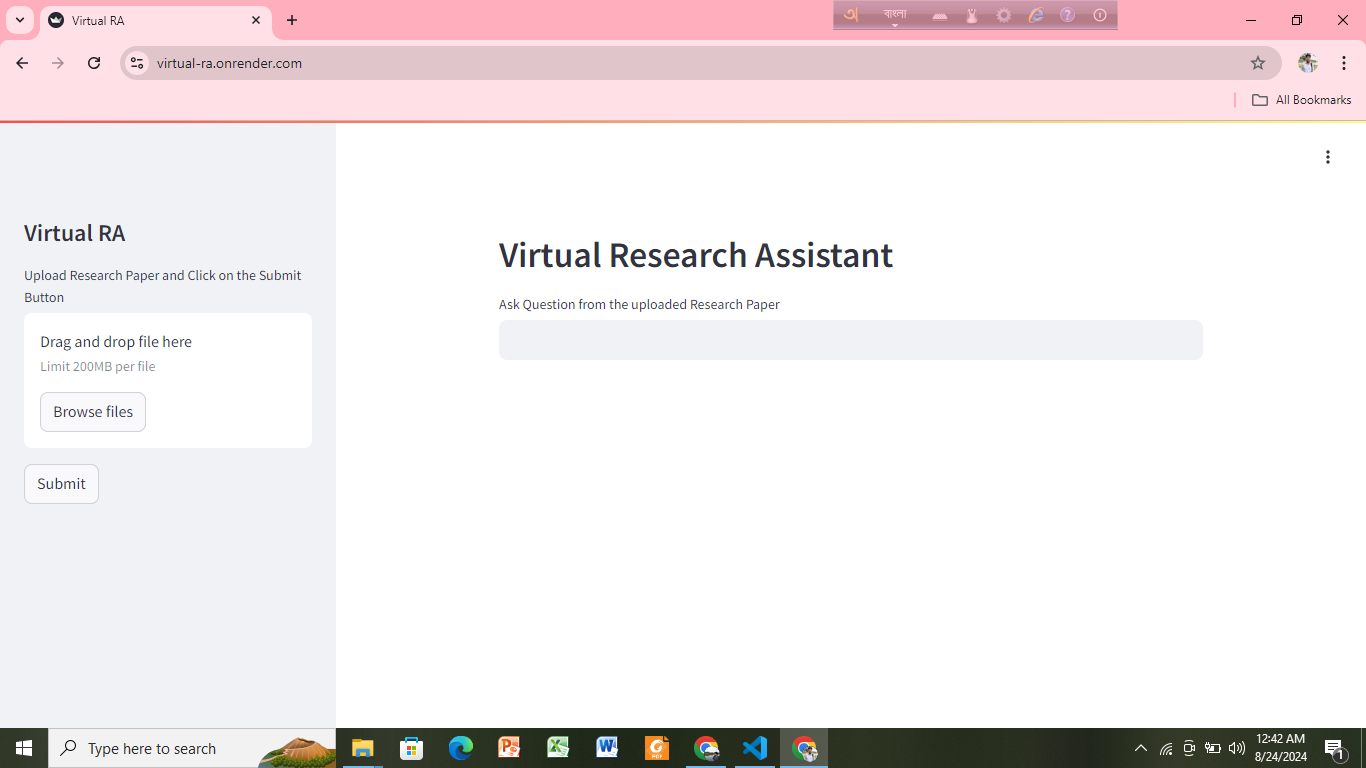
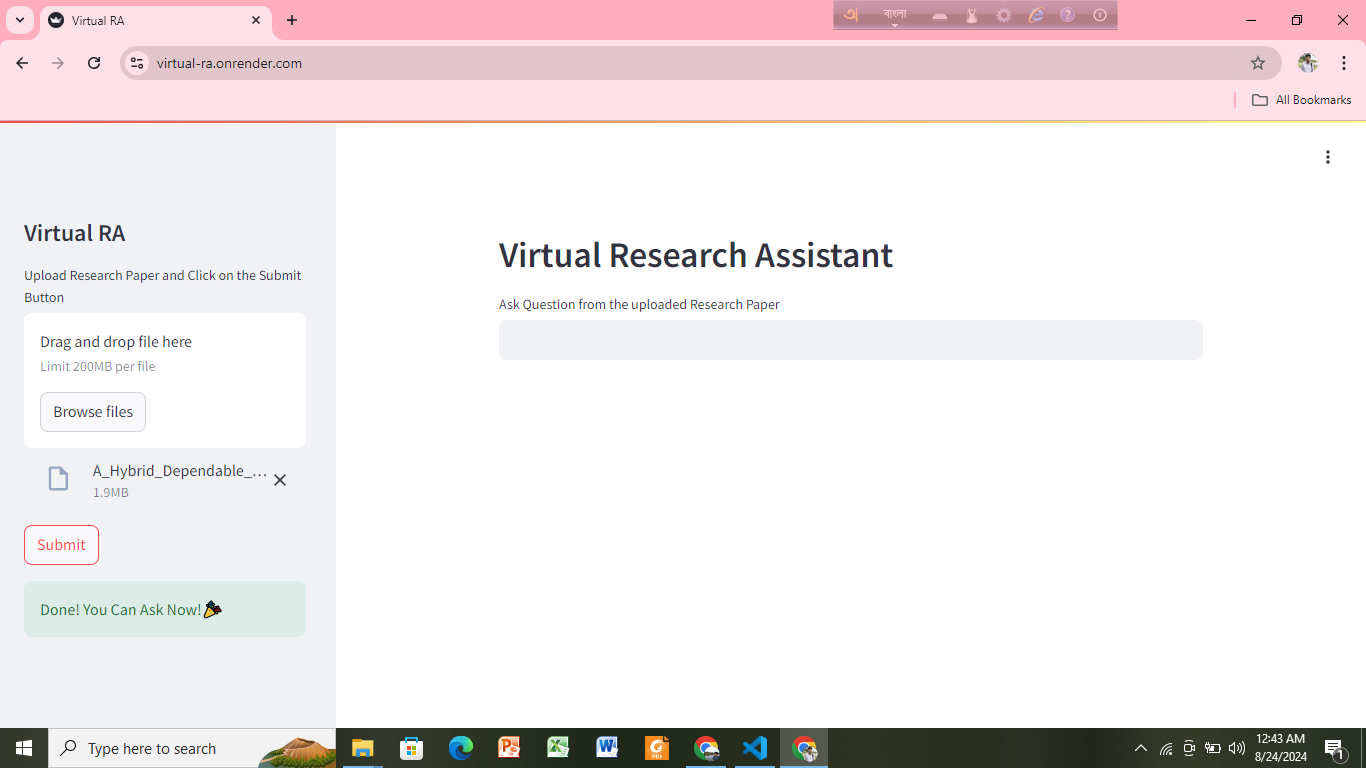
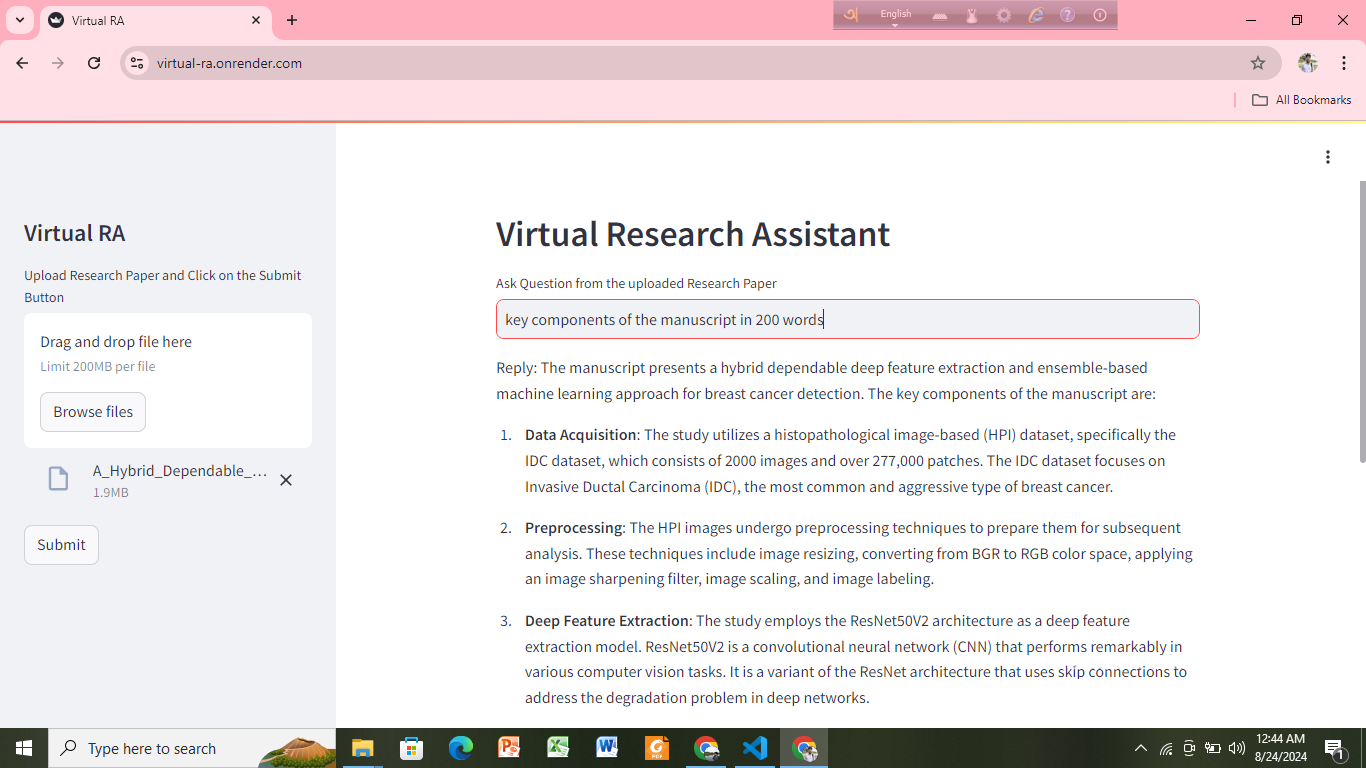
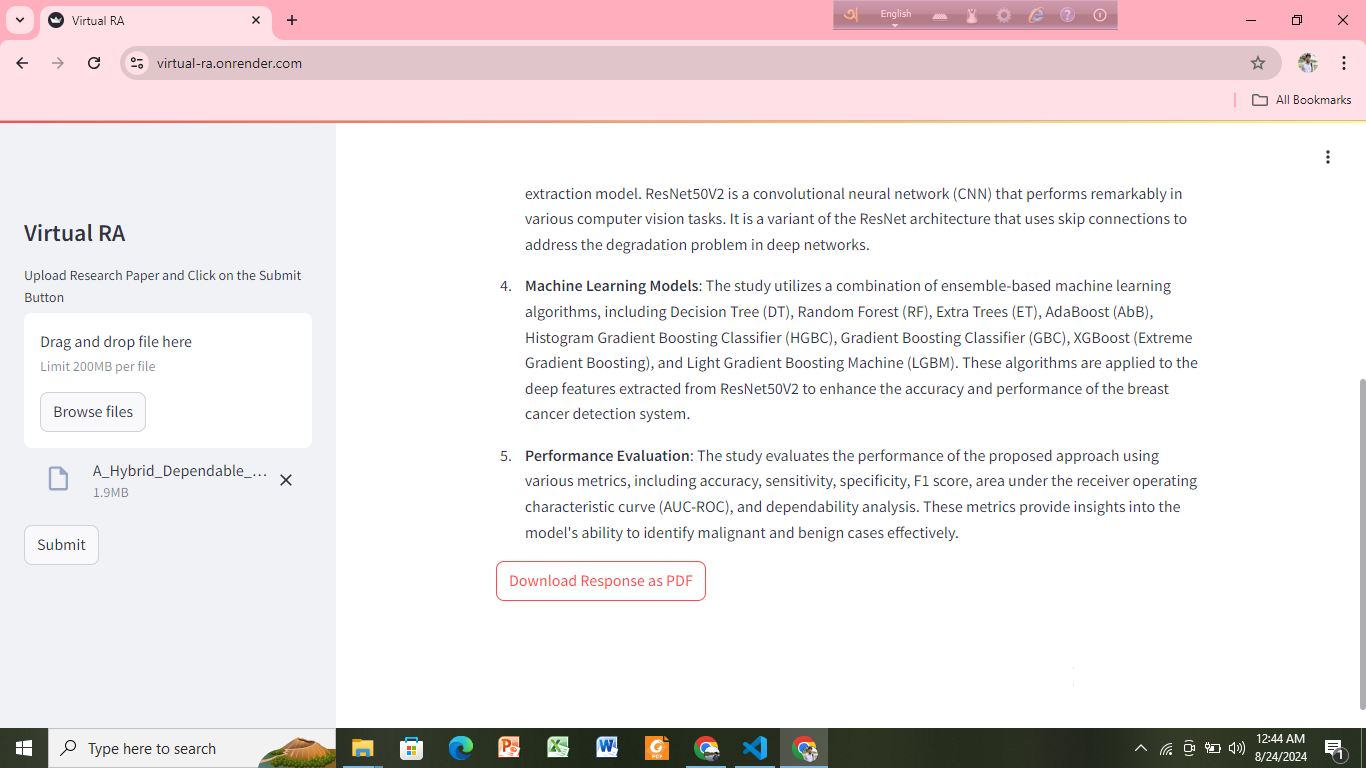
Virtual Research Assistant for Research Paper Analysis
Objective: To create a Virtual Research Assistant that helps users easily upload research papers, ask questions, and receive accurate answers, leveraging Gemini Pro for efficient analysis and insights.
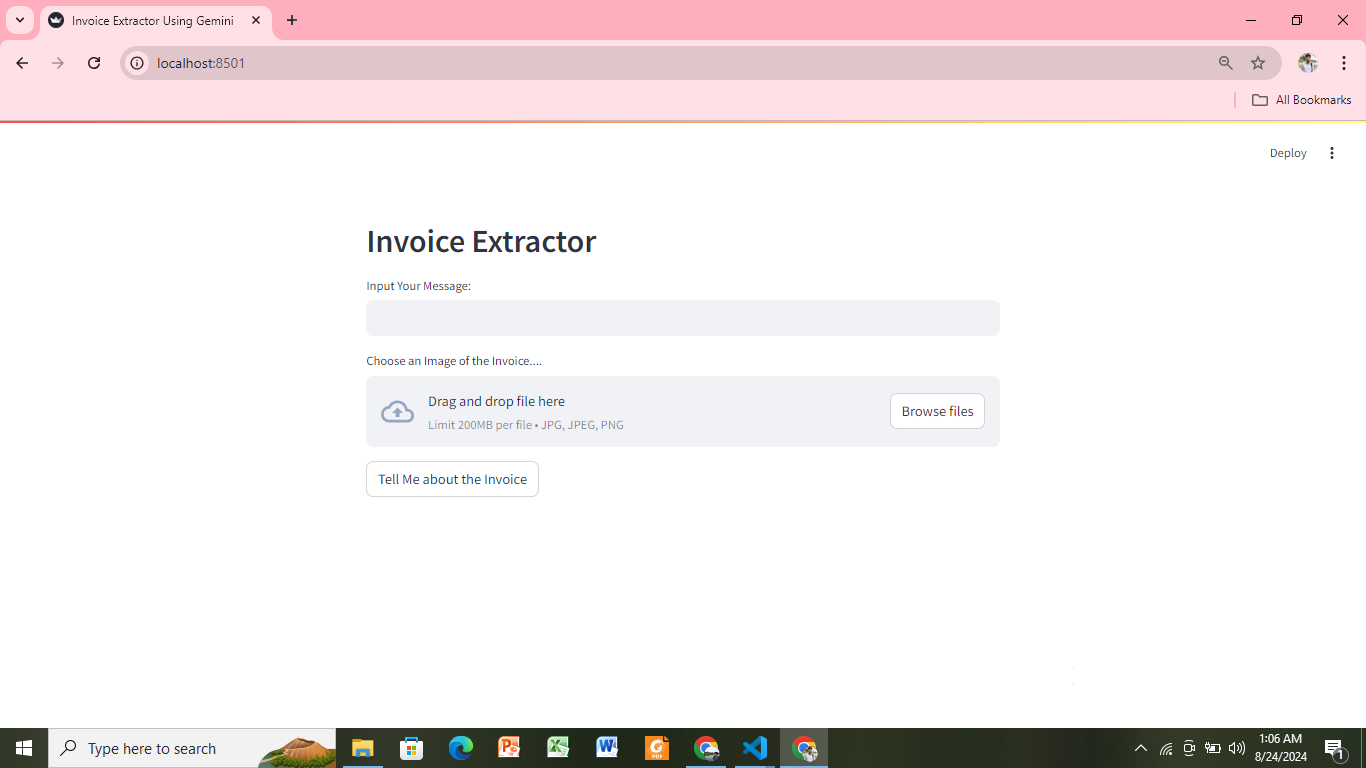
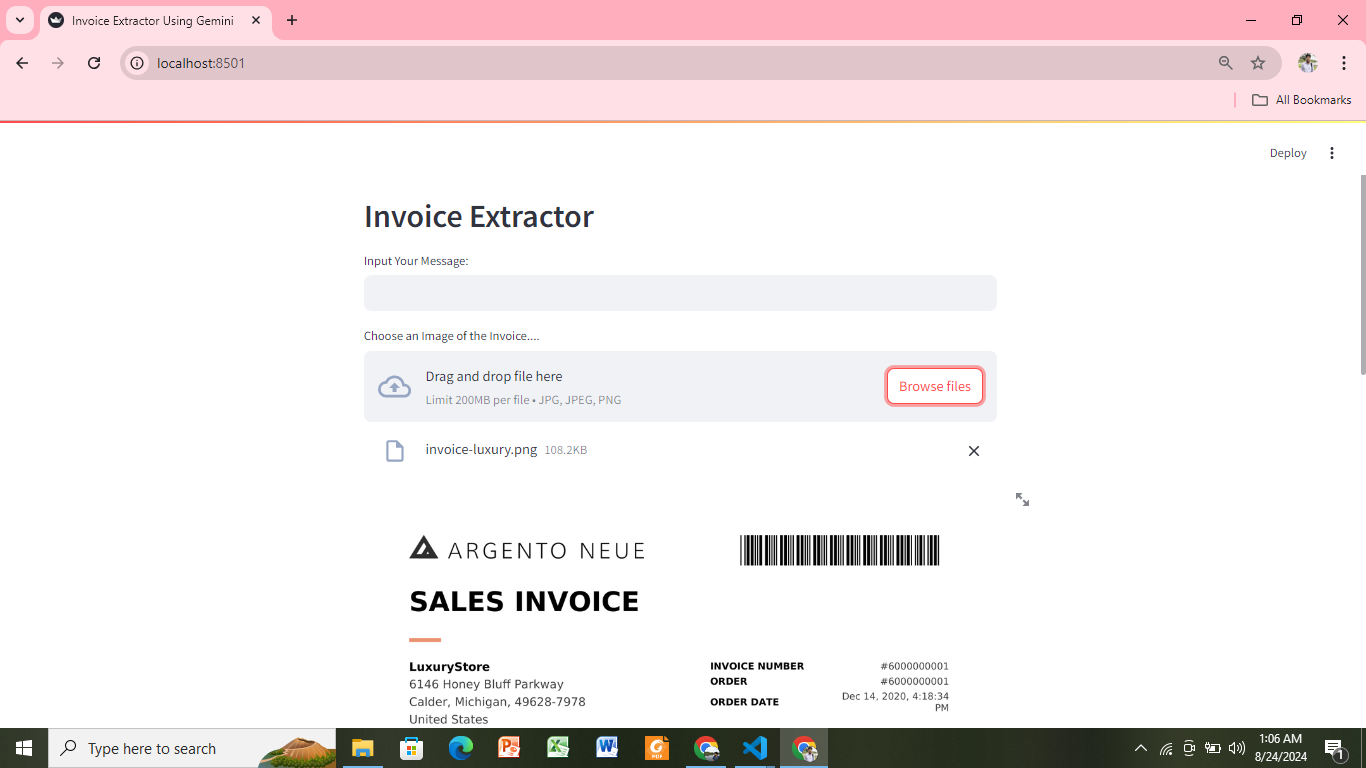
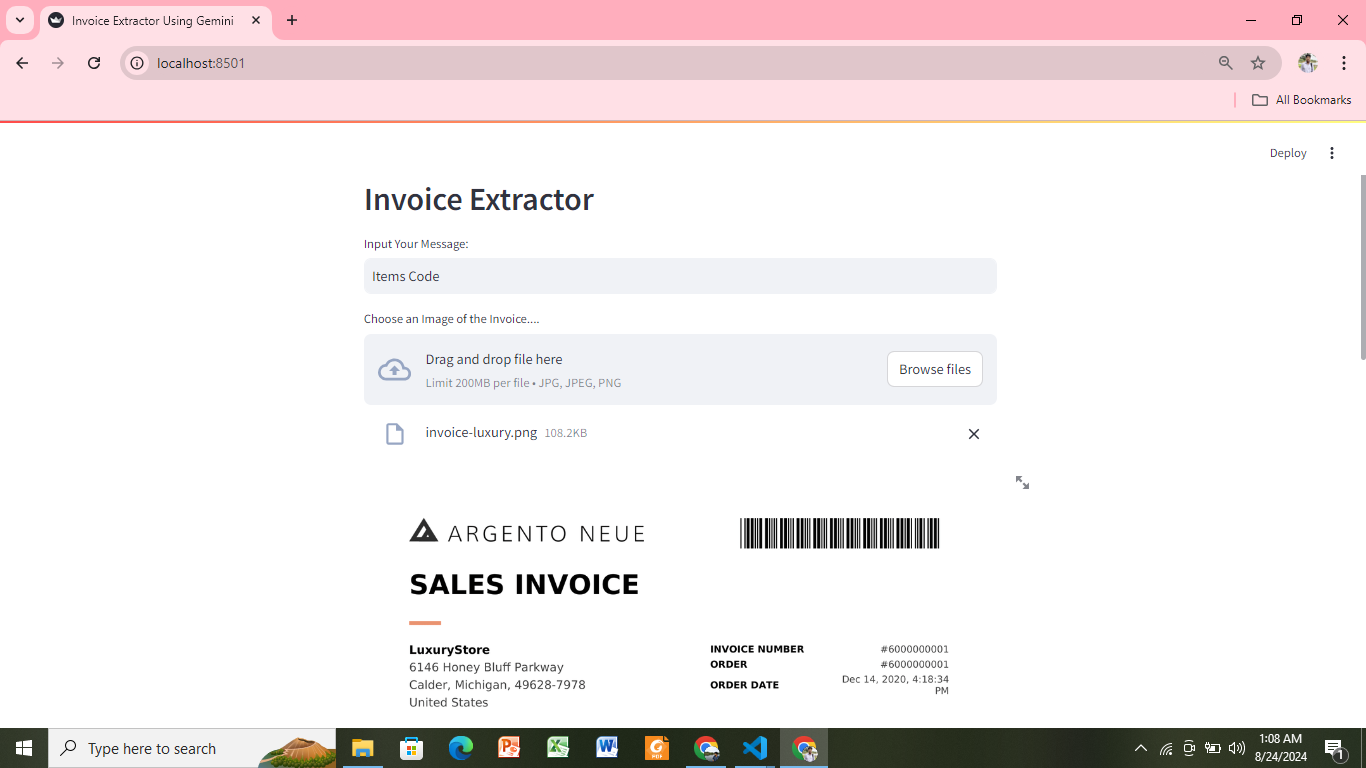
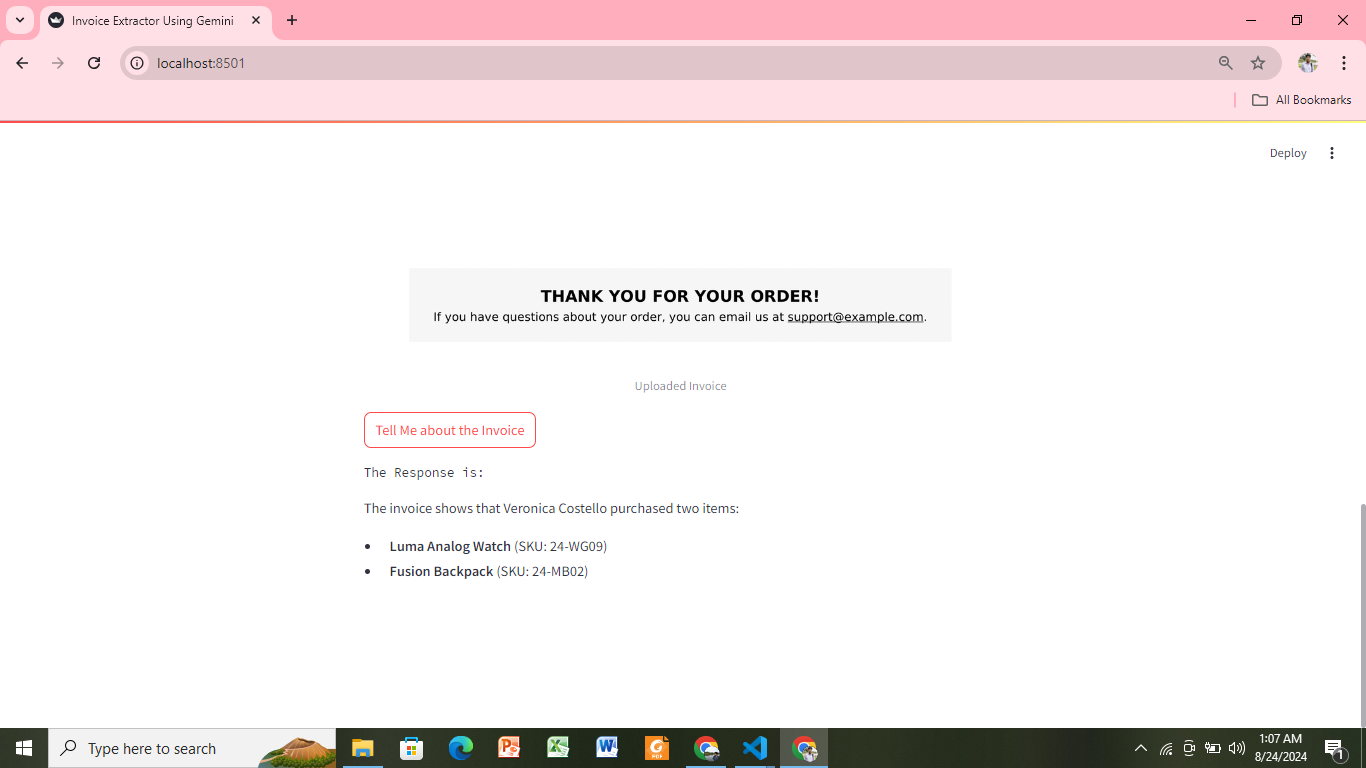
Information Extraction from Image Using Gemini
Objective: Information extraction from the image the invoice and medical prescriptions.
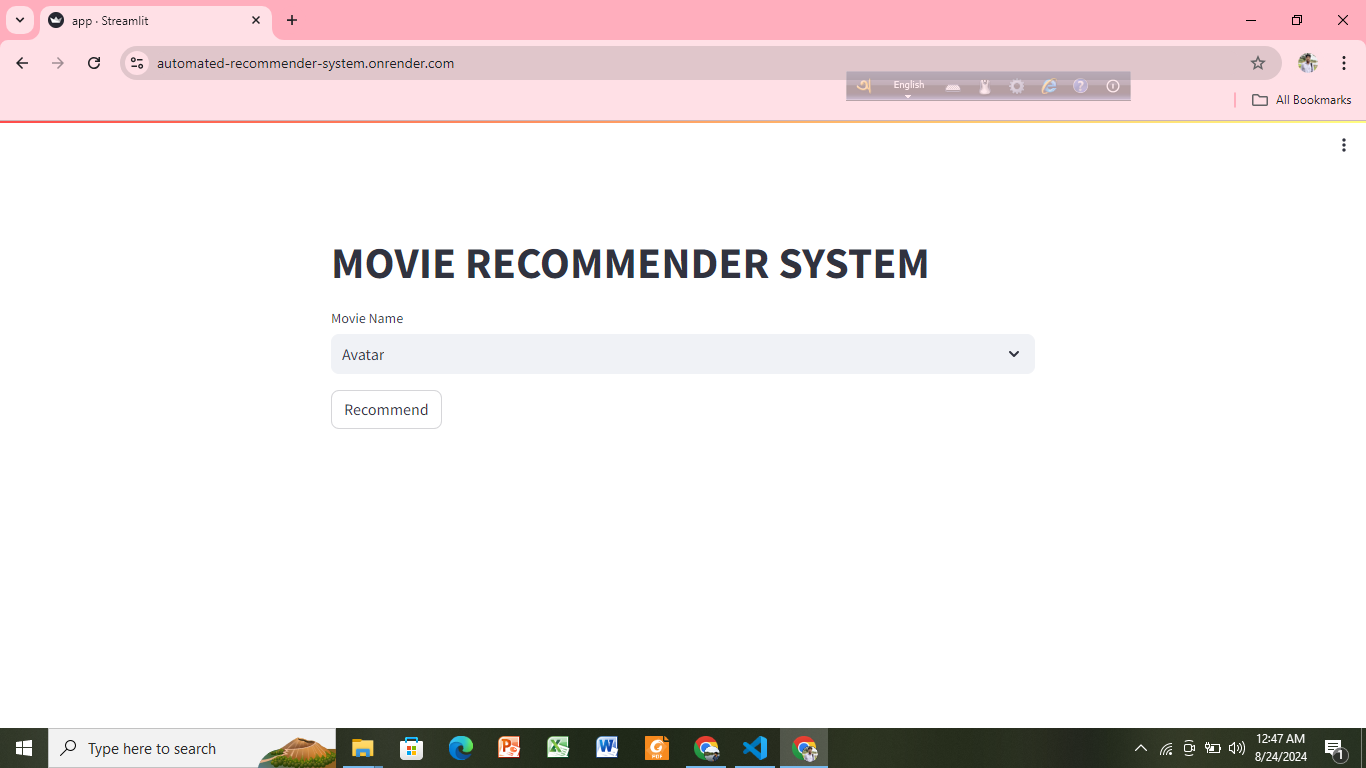
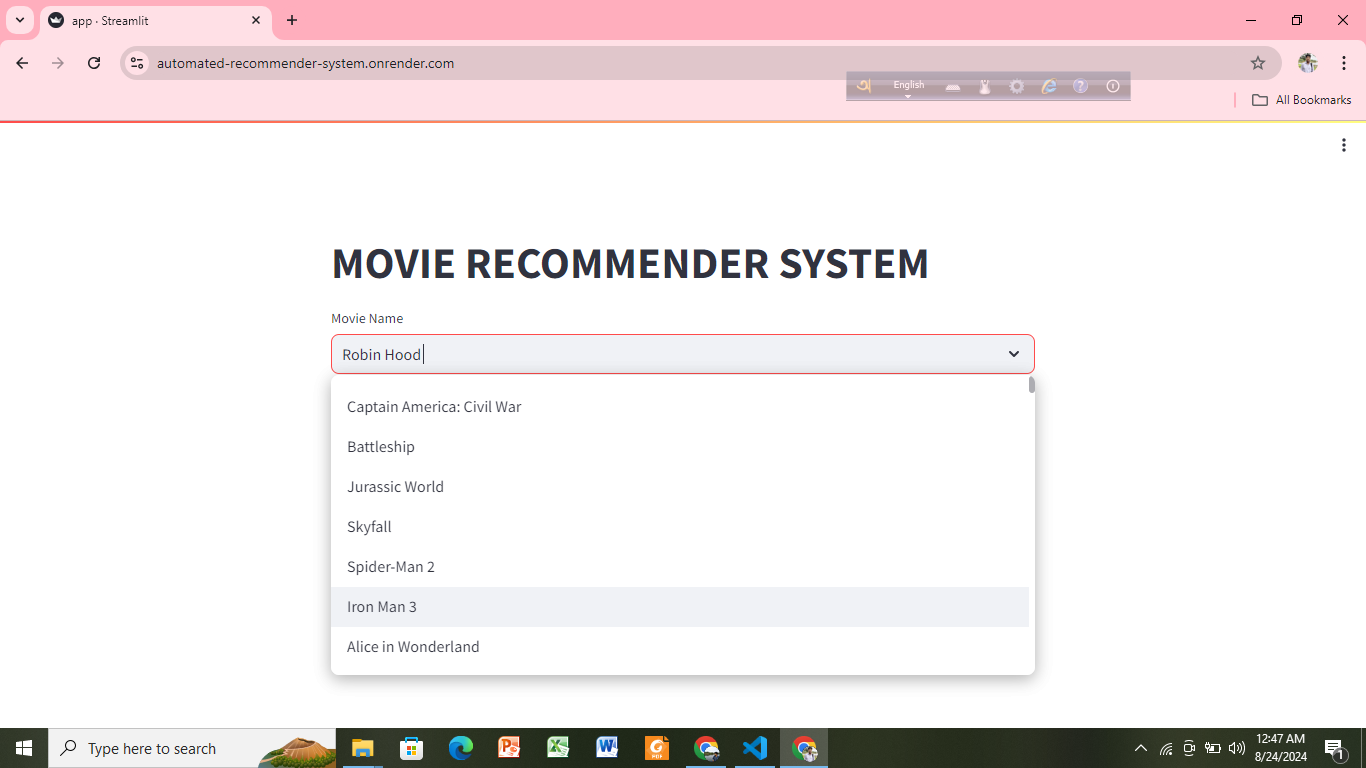
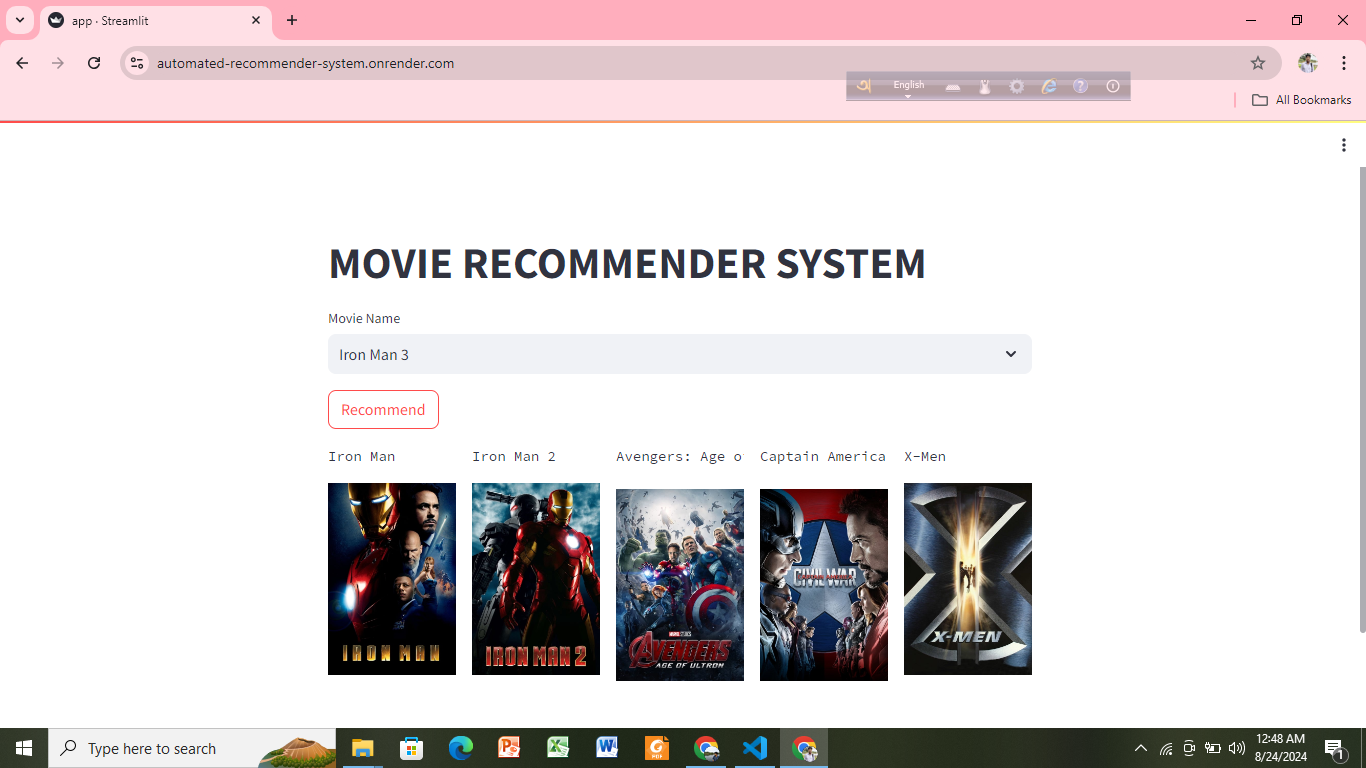
Automated Recommender System (Content Based)
Objective: Suggest personalized content or items to users based on their preferences, either by analyzing the characteristics of the items.
Understanding Customer's Degree of Satisfaction
Objective: Understanding The Consumer’s Degree of Satisfaction using Machine Learning Approach.
Line Following Robot (Course Project)
Objective: Autonomously navigate along a predefined path by detecting and following a line on the ground..
Get in Touch